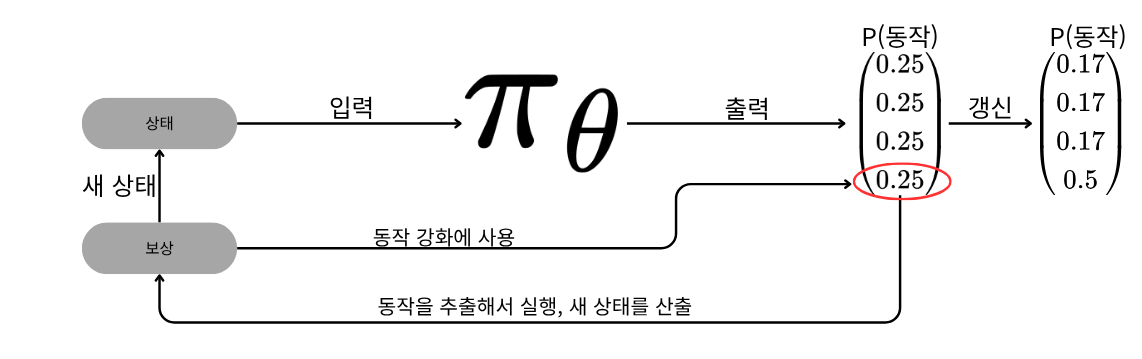
지난 글에선 REINFORCE 알고리즘을 공부했다.이 알고리즘은 간단한 CartPole 예제에는 잘 작동했지만, 좀 더 복잡한 환경의 강화학습에는 그리 잘 통과하지 않는다. 한편, DQN의 경우 이산적인 동작 공간에서 상당히 효과적이지만, 입실론-그리디 정책같은 개별적인 정책 함수가 필요하다는 단점이 있다. 이번 글에서는 REINFORCE의 장점과 DQN의 장점을 합친 actor-critic(행위자-비평자)라는 알고리즘을 소개한다.이 모델은 여러 문제 영역에서 최고 수준의 성과를 낸 바 있다.REINFORCE 알고리즘은 일반적으로 일회적 알고리즘(에피소딕, episodic algorithm)으로 구현된다.이는 에이전트가 하나의 에피소드 전체를 끝낸 후에야 그 에피소드에서 수집한 보상들로 모델의 매개변수들..