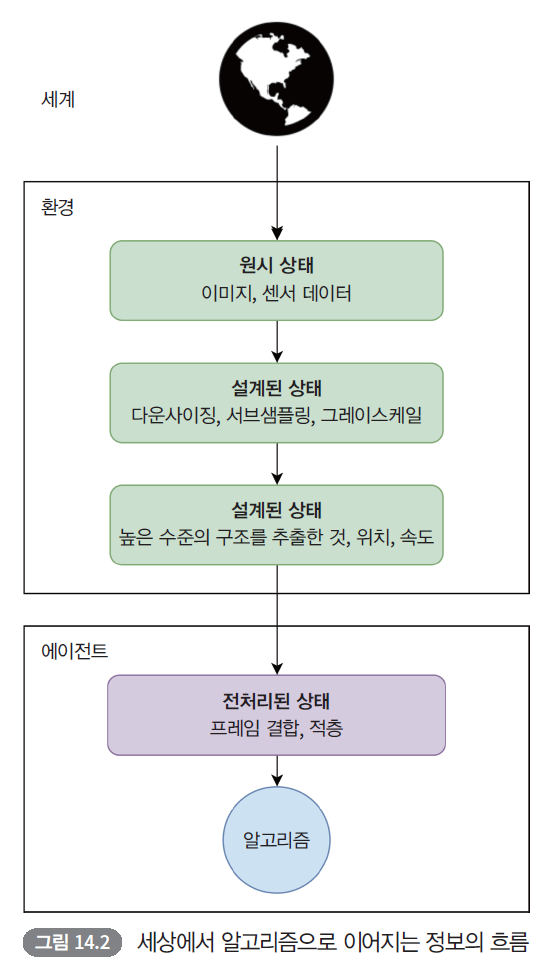
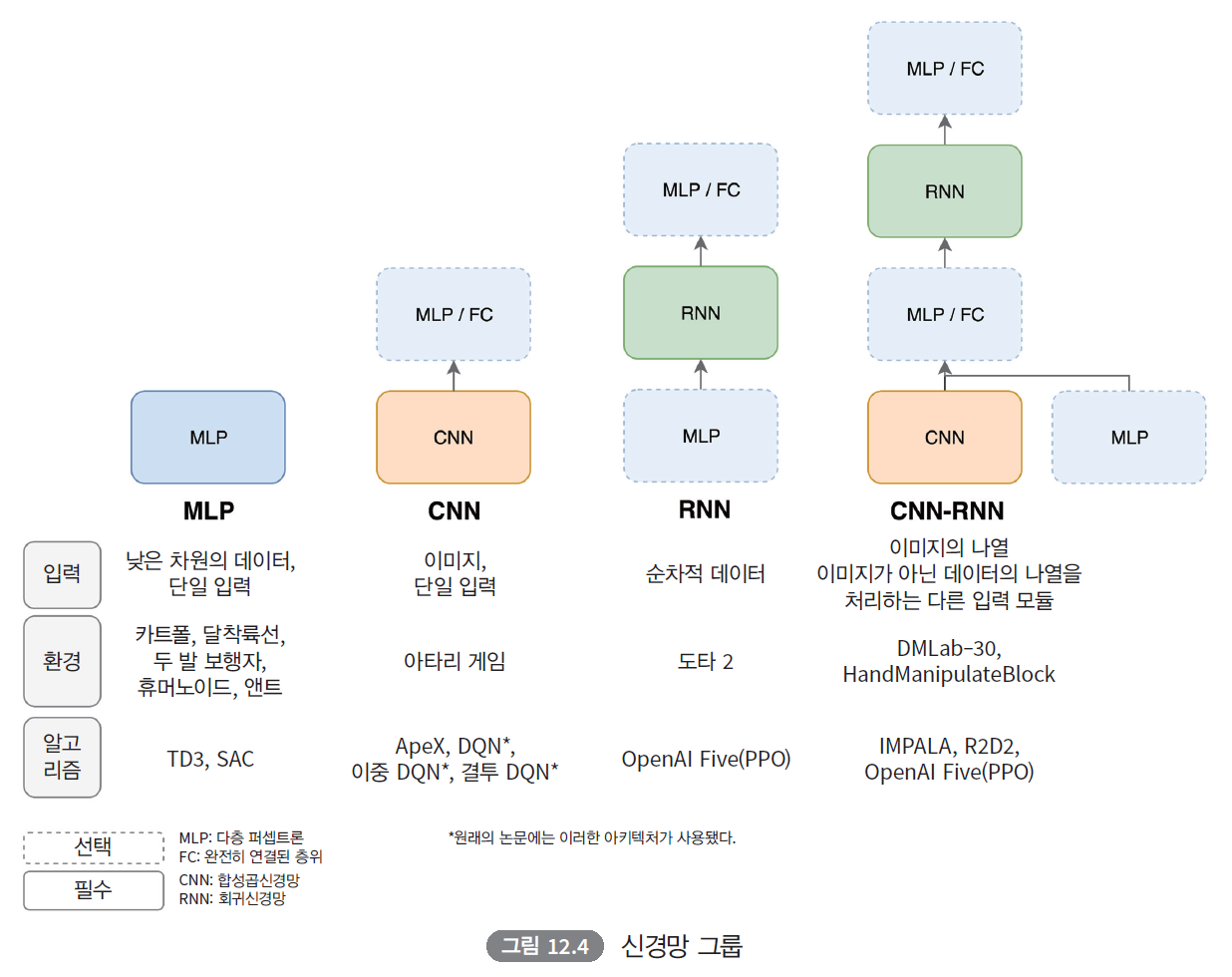
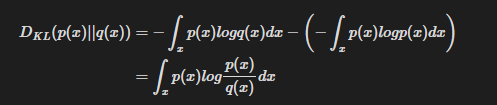본 글은 "Proximal Policy Optimization Algorithms” (Schulman, Wolski, Dhariwal, Radford, Klimov, 2017)를 읽고 리뷰한 내용입니다. Proximal Policy Optimization AlgorithmsWe propose a new family of policy gradient methods for reinforcement learning, which alternate between sampling data through interaction with the environment, and optimizing a "surrogate" objective function using stochastic gradient ascent. Wher..