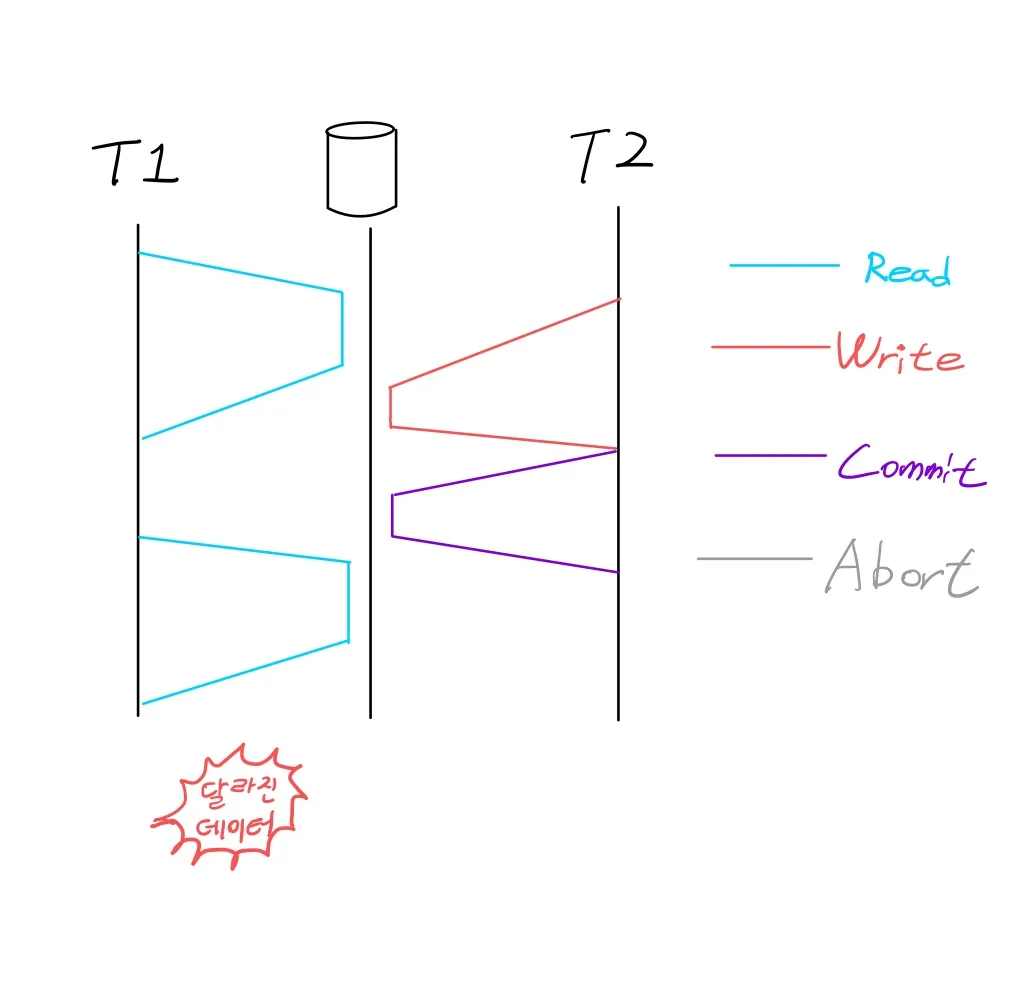
동시에 실행되는 트랜잭션들은 서로를 방해하지 말아야 한다. 예를 들어, 한 트랜잭션이 여러 번 쓴다면 다른 트랜잭션은 그 내용을 전부 볼 수 있든지 아무것도 볼 수 없든지 둘중 하나여야 하고, 일부분만 볼 수 있어서는 안된다. (데이터 중심 애플리케이션 설계, 228p)
Database System Concepts(silberschatz, 2019)에서는 이를 직렬성 이라는 용어로 공식화한다. 직렬성은 각 트랜잭션이 전체 DB에서 수행하고 있는 유일한 트랜잭션처럼 동작함을 의미한다. (해당 내용은 아래에서 좀 더 깊이 다룰 예정이다.) 하지만, 현실적으로 이 직렬성은 성능 리스크가 크기 때문에, 일반적으로 잘 사용하지 않는다.
그 대신, MySQL과 같은 DB는 직렬성보다 보장이 약한 스냅샷 격리로 격리성을 약하게 보장한다. 해당 내용은 다음 글에서 제대로 알아보도록 하고,(작성 예정) 지금은 격리성의 이해에 집중해보도록 하자.
트랜잭션 격리 수준은?
트랜잭션 격리 수준은, 해당 트랜잭션의 격리성에 대하여, 어느정도로 깐깐한 기준을 세워 놓느냐의 의미이다.
실제 스프링에서 트랜잭션 별 Isolation Level을 설정할 수 있는데, 이는 해당 트랜잭션이 어느정도의 격리성 기준을 사용할 것인가를 지정하는 의미이다. 격리성의 기준은 충돌의 정의에 강력한 영향을 미치며, 해당 기준을 만족시키지 못하면, 대처 방법은 다른 설정에 의해 관리된다.
우리는 이때 대처 방식으로 아래와 같은 대처 알고리즘을 “따로 설정(혹은 기본 설정 사용)”하게 되는 것이다. 깐깐한 기준을 가질수록 작업 순서 수준의 데드락이 발생할 가능성이 높아지고, 이에 대한 데드락 해결 알고리즘은 별개의 옵션이다.
사용 가능한 데드락 대처 알고리즘
주기적 사이클 확인
락 대기 타임아웃
et cetra
충돌의 정의와 충돌 동등의 정의를 이해하면 알 수 있겠지만, 락 경합에 대해서만 데드락이 발생하는 것이 아니라, 격리성에 의한 작업 순서 결정에서도 데드락이 발생할 수 있다.
“격리성" 이라는 개념 자체가 본질적으로 추상적인 개념이고, 실제 구현에 따라 달라지는 영역이 많기 때문에, 이 추상적인 부분(충돌 동등의 기준)에 대한 이해를 위해선, 직접 구현을 해보며 알아가야 한다.
(데이터 중심 애플리케이션 설계 - 223p 참고)
다양한 용어가 비슷한 의미를 갖는 경우가 많기 때문에, 다음 용어에 대한 구분을 확실하게 지어두길 바란다.
충돌 동등
이전 글에서 다룬 내용이지만, 중요한 내용이니 한번 더 간단하게 다루도록 하겠다.
Conflict란?
서로 다른 트랜잭션 내 작업 간의 간섭을 이야기한다.
(잠시 버전 관리, MVCC 관련 내용을 잊고, 한 데이터가 오직 한곳의 저장공간에만 존재하고, UNDO LOG와 같은 데이터는 없다고 생각해보자.)
충돌의 종류에는, 크게 다음과 같은 세가지가 있다.
Read-Write Conflict
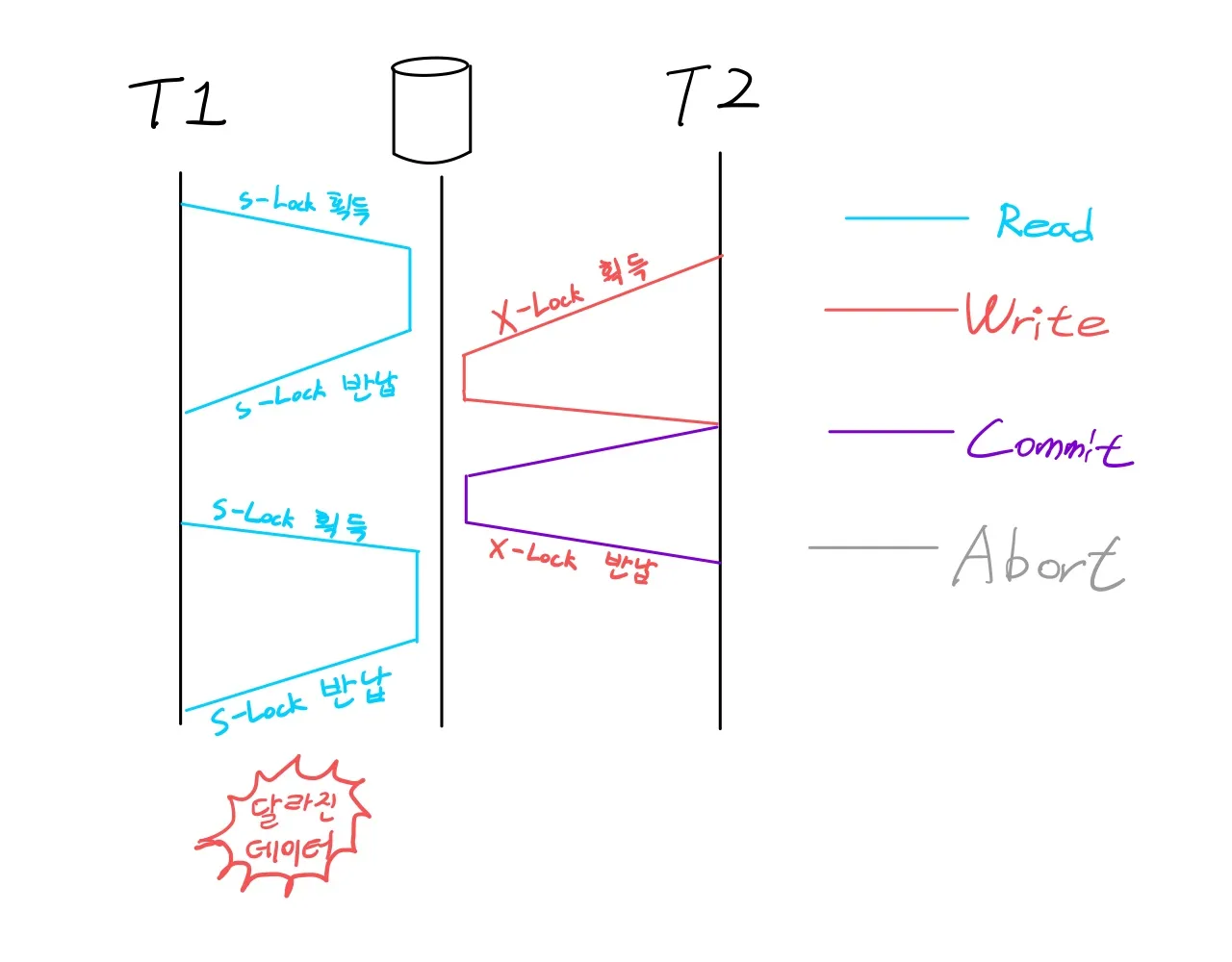
Unrepeatable Read
첫번째 Read 이후, Write 후에 다시 Read 하면 결과가 달라지는 문제
Write-Write Conflict
Dirty Write
커밋되지 않은 데이터 사이에 덮어씌우기가 일어나는 것
먼저 실행한 Write 연산이 사라지는 문제가 발생한다.
일반적으로 대부분의 DB에서 Dirty Write는 반드시 차단한다.
Write-Read Concflict
Dirty Read
Write 된 내용이 커밋되지 않았는데 읽히면 안된다
앞의 Write 가 롤백되면, 문제가 된다.
충돌 동등이란?
먼저 직렬성을 이야기하기 전에, 충돌 동등이라는 관계를 정의하고 들어가보자.
스케줄
여러 트랜잭션의 연산들이 실행되는 순서
충돌 동등(Conflict Equivalent)
동일한 트랜잭션 집합 간에 서로 다른 순서를 가진 스케줄이 Conflict 가 없을 경우
서로 다른 두 스케줄이, 충돌 동등하다 라고 정의한다.
간단히 이야기하면,
"Read" 연산 사이엔 순서가 상관이 없다
"Write" 가 존재하는 순간, 순서가 중요해진다.
이걸 일반화한게 Conflict 개념이다.
두 스케줄 간에, 순서만 다를 뿐 Conflict 연산 쌍의 순서가 동일하다면, 이를 Conflict Equivalent 라고 정의한 것이다.
Conflict Serializability
우리는 앞에서, 격리성이 “직렬성”이라는 용어로 공식화되어 다루어진다고 이야기했다. 여기서 충돌 동등 개념을 사용하여, 다른 스케줄을 가지며, 직렬성을 갖는 트랜잭션의 순서를 상상해보자.
가장 간단한 방법은, 실제로 트랜잭션을 “직렬화”시켜서 동작시키는 것이다.
결과적으로 직렬성에서 이야기하는 유일한 트랜잭션처럼 동작한다라는 것은, “서로 다른 트랜잭션 간에 Conflict 가 없다“라고 이야기할 수 있다.
직렬 스케줄과 충돌 동등한가?
그렇다면, 어떻게 현재 스케줄이 직렬 스케줄과의 충돌 동등인지를 파악할 수 있을까?
우리는 이때, 그래프 이론을 간단하게 활용하여
1. 한 스케줄에 대하여, 스케줄 내 트랜잭션을 DAG 화시킨다.
정점
스케줄 내 트랜잭션
간선
트랜잭션 간 어떠한 데이터에 대하여 연산의 순서
T1: Write(D) -> T2: Read(D)
T1: Read(D) -> T2: Write(D)
T1: Write(D) -> T2: Write(D)
2. 해당 DAG를 위상정렬한다.
이를 우리는 Serializability Order라고 할 수 있게 된다.
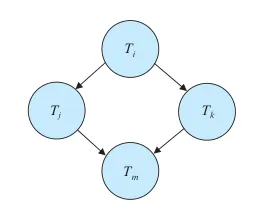
물론 이때, 아래와 같이 사이클이 있으면 애초에 직렬가능하지 않다.
주의) 같은 결과를 낸다고, 항상 충돌 동등한 것은 아니다.
지금부터 예시를 보며, 트랜잭션의 고립 수준 개념을 정리해보자.
우리가 익숙한 몇가지 락의 개념을 사용해서, 각 고립 수준의 정확한 기준을 의미해보자.
주의) 이 구현 자체가 고립 수준을 의미하는 것은 아니다.
각 고립 수준의 구현을 통해, 해당 고립 수준이 어느정도의 기준을 갖는지를 이해해보자는 취지이다.
설명을 위한 선수 내용: 잠금의 종류
이미 알고 있을 수 있겠지만, 실제로 고립 수준을 구현해보기 위해, S-Lock, X-Lock, Range-Lock을 정의해보자.
Shared-Lock(S-Lock)
읽기를 막지 않음
쓰기를 막음
여러 트랜잭션이 동시에 획득 가능
Exclusive-Lock(X-Lock)
읽기를 막음
쓰기를 막음
유일한 트랜잭션만 획득 가능
이해를 위해, X-Lock과 S-Lock의 상호작용 중 두가지 특징을 기억해야 한다.
X-Lock 의 획득 시도 발생 시, X-Lock의 제공 준비를 위해서 S-Lock의 제공을 중단함으로써 X-Lock의 Starvation을 해결한다.
락 없이 접근하면?
락 검사 자체를 하지 않음
위의 락이 제공하는 기능 자체를 무시함
한마디로, 오히려 “즉시 접근이 가능”해진다.
일반적으로 MVCC 환경의 경우, 즉시 접근이 가능해지더라도 안전한 버전의 데이터를 조회하게 되므로
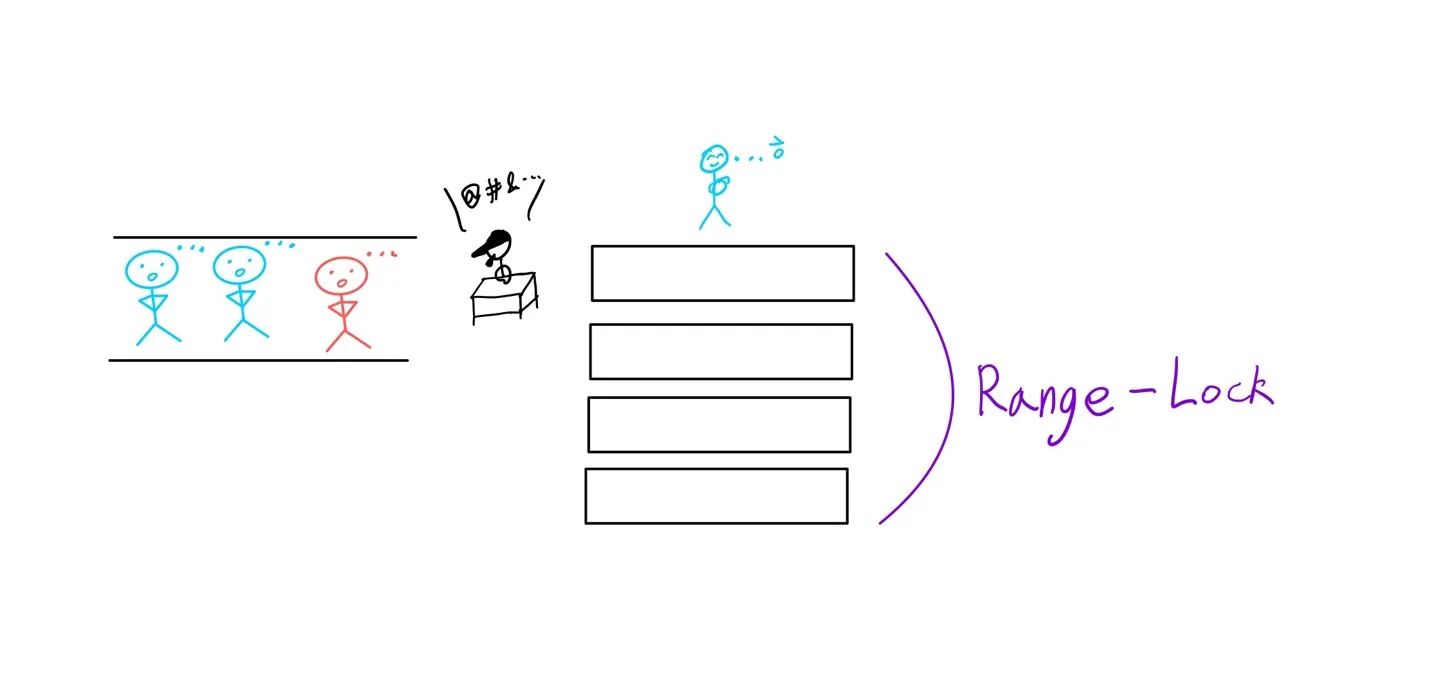
Range-Lock
팬텀 리드를 막기 위한 MySQL의 갭 락과 같은 기능(갭 락이 이 Range-Lock을 구현한 구현체이다.)
인덱스 잠금 + 범위에 잠금을 거는 방식으로 동작한다.
삽입과 삭제를 막는데 집중하는 잠금이다.
특정 조건(레인지 락의 범위)을 만족하는 삽입/삭제/키 값 변경 쿼리를 대기시킨다.
참고: Range-Lock과 X-Lock/S-Lock은 다른 범주에 있으며, Range Lock과 MECE 범주를 이루는 다른 개념으로는 Record Lock, Table Lock이 있다.
저수준의 고립성의 레벨 구현은 두가지 기능의 조화로 구현된다
작업별 락의 종류
락의 해제 시점
Serializable
읽기 작업
S-Lock 획득
끝까지 유지
필요한 범위에 Range-Lock 획득
끝까지 유지
쓰기 작업
X-Lock 획득
끝까지 유지
X-Lock 의 획득 시도 발생 시, X-Lock의 제공 준비를 위해서 S-Lock의 제공을 중단함으로써 X-Lock의 Starvation을 해결한다.
필요한 범위에 Range-Lock 획득
끝까지 유지
추구하는 고립 수준
직렬성 스케줄과 충돌 동등한 스케줄을 목표로 검사한다.
Serializable 고립 수준은 직렬성과 충돌 동등한 스케줄을 구현하며, 쓰기와 읽기 작업을 가리지 않고 단일 작업만 허용하기 때문에, 팬텀 리드를 제거한다.
그 대신, 동시 처리를 전혀 고려하지 않은 설계이기 때문에 제일 느리다. 성능 상의 문제가 심각하기 때문에, 특정 DB에서는 구현조차 하지 않는 경우도 많다.
Repeatable Read
읽기 작업
S-Lock 획득
끝까지 유지
쓰기 작업
X-Lock 획득
X-Lock 의 획득 시도 발생 시, X-Lock의 제공 준비를 위해서 S-Lock의 제공을 중단함으로써 X-Lock의 Starvation을 해결한다.
끝까지 유지
추구하는 고립 수준
Read하는 동안에는 데이터가 일절 변경되지 않도록 검사한다.
새로운 데이터의 추가는 고려하지 않는다.
위와 같은 고립 수준은 적어도 읽기가 발생하는 순간에는 쓰기 작업을 차단하기 때문에, 읽는 도중에 데이터가 바뀌는 현상을 제거하고, 따라서 Unrepeated Read를 제거할 수 있게 된다.
하지만, 예상치 못한 데이터의 삽입과 삭제는 발생할 수 있기 때문에, 팬텀 리드가 발생하고, 어떠한 DB는 이런 팬텀 리드를 막기 위해, Range-Lock 개념을 여기서도 도입하기도 한다.
하지만 본질적으로 트랜잭션 고립 수준을 Serializable한 수준까지 검사하지 않기 때문에, 완벽한 Phantom Read의 차단을 보장할 수는 없다.
Read Committed
읽기 작업
접근 시 S-Lock 획득 후, 즉시 반납한다.
S-Lock 을 락 검사용으로 사용하고, 즉시 반납하기 때문에, X-Lock 잠금을 갖고 있는 트랜잭션이 먼저 커밋되면, 데이터가 바뀔 수 있다.
Read Committed 의 경우, 2PL을 엄격히 따르지 않기 때문에 가능한 방식이다.
2PL(2-Phase Locking)이란? 한번 락의 단계를 낮추는 순간, 다시 락의 단계를 높힐 수 없다는 규칙이다. 간단한 예시로는 한번 배타 잠금을 공유 잠금으로 낮추는 순간, 다시 배타 잠금으로 승격시킬 수 없다는 규칙이다.
쓰기 작업
X-Lock 획득
끝까지 유지
추구하는 고립 수준
커밋된 데이터라면 읽어도 된다는 기준을 갖고 있다.
따라서 해당 고립 수준은, 이전과 읽은 값이 달라지더라도 해당 값이 커밋된 데이터라면 허용한다.
Read Commited 고립 수준은 S-Lock을 읽기 작업에 획득하려고 시도함으로써 만약 쓰기 작업이 진행되고 있었다면 X-Lock 이 끝날때까지 대기하고, 쓰기 작업이 커밋을 수행하며 X-Lock을 반납하는 순간 다시 S-Lock을 획득(후 즉시 반납)하며 읽기 작업을 수행하기 때문에, 적어도 커밋되지 않은 데이터에 의한 영향(Dirty Read)은 차단한다.
또한 트랜잭션이 끝날때까지 S-Lock을 계속 갖고 있지 않기 때문에, 읽기 작업을 한번 마친 트랜잭션 도중에 다른 쓰기 작업이 들어와 데이터를 변경할 가능성이 존재한다. 따라서 Unrepeatable Read 가능성이 존재한다.
Read Uncommitted
실제로는 Serializable보다 더욱 쓰이지 않는, Read Uncommitted에 대해 알아보자.
읽기 작업
락 획득 X
락을 검사하지 않는다!
X-Lock의 읽기 잠금을 무시한다.
쓰기 작업
X-Lock 획득
끝까지 유지
추구하는 고립 수준
사실상 고립을 추구하지 않는다.
다른 트랜잭션의 쓰기 작업으로 값을 변경하더라도, 이를 그대로 읽는다.(Dirty Read)
다른 트랜잭션에 의한 방해를 허용하는 고립 수준이다.
위 내용은 이해를 위한 저수준의 Lock 구현 방식이었다.
또한, 해당 격리 수준은 임의의 예제일 뿐, 실제로 모든 DB 벤더사들이 위 4가지 기준을 완벽히 맞춰 사용자가 선택할 수 있도록 구현하지 않고, 자신들의 최적화 기법에 맞춰 최대한 효율적인 고립 수준을 구현하려 한다.
실제로는 락 + MVCC(스냅샷 고립)으로 섬세하게 구현하며, 이 내용을 다음 시간에 제대로 알아보도록 하자. (작성예정)
참고 자료
Database System Concepts, silberschatz(2019)
데이터 중심 애플리케이션 설계, Martin Kleppmann, 정재부 외 2인 역(2023)